
Over the past few weeks we’ve watched an ugly repricing across software and services stocks — including names the market treated like near-permanent compounders. The “buy it, forget it, check back in five years” confidence has been replaced by a sharper question:
What exactly are we paying for — and how durable is it in an LLM world?
It’s tempting to label this “AI panic”. Markets love a shiny new thing, they overreact, they punish, and then everyone moves on.
I don’t think it’s that simple. And I also don’t think the answer is “AI kills vertical SaaS”.
I’ve spent a meaningful chunk of my career building vertical software and data products – tools that sit inside serious workflows, become muscle memory, and help professionals make (and defend) decisions. More recently, I’ve built and invested around AI-enabled workflows too. So I’ve been on both sides of the shift: I’ve built products that LLMs can unbundle, and I’m building the capabilities that do the unbundling.
My operator’s take (with a board member’s instinct for what breaks first) is this:
The sell-off is structurally justified, but the market is probably exaggerating the timing.
Moats don’t evaporate overnight. Procurement cycles don’t compress just because models get better. Most enterprise revenue doesn’t fall off a cliff – it erodes: discounts at renewal, modules unbundled, pricing power chipped away, and value reframed as “we’ll keep you, but we’re not paying that anymore.”
What we’re watching in real time is the repricing of pre-LLM moats — especially moats that were really interface + workflow habit, now challenged by a new layer users increasingly prefer: natural language, instant synthesis, and outcomes without caring who sits behind the answer.
Here’s the framework I use to make sense of it.
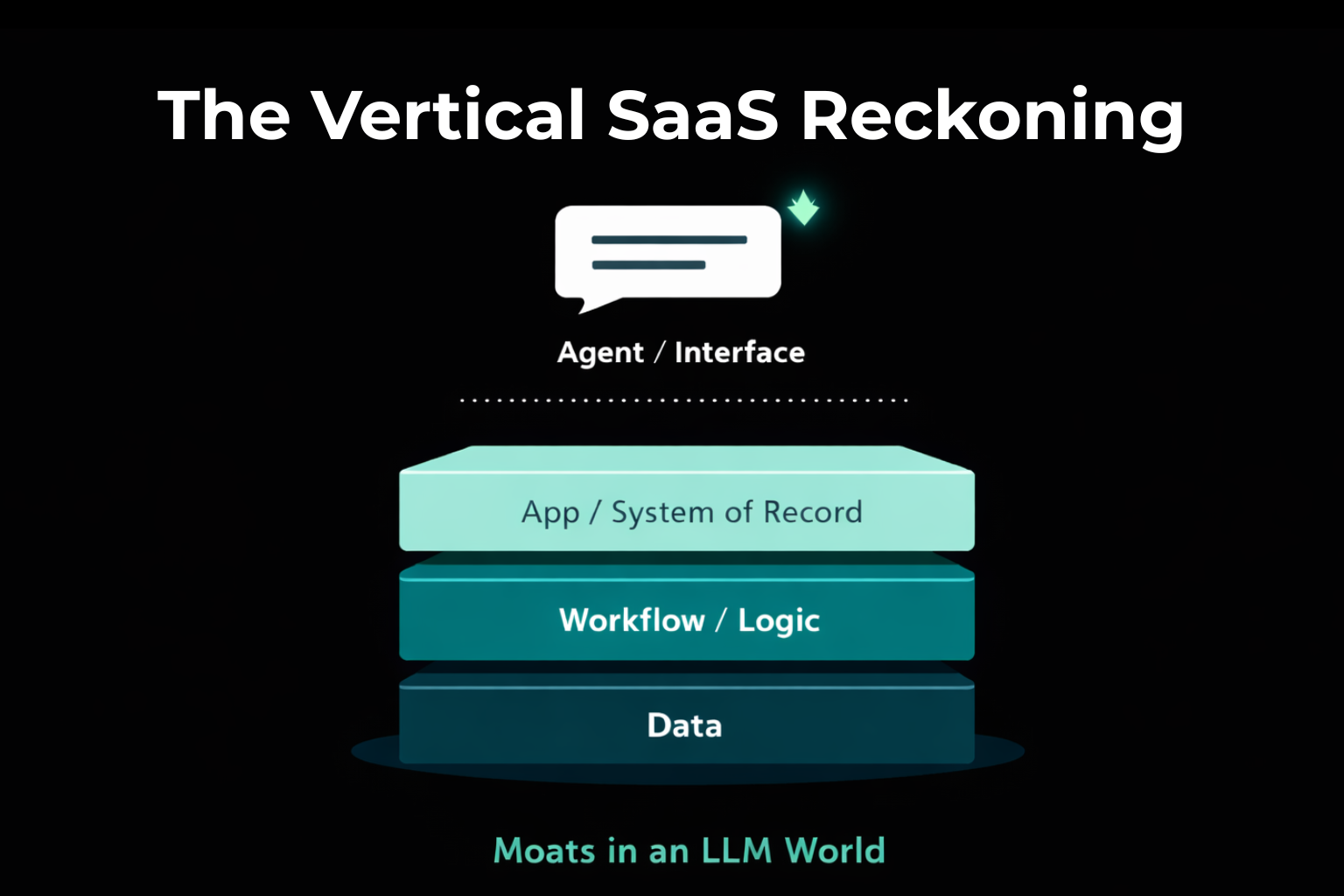
What vertical software was (and why it worked)
Great vertical software isn’t “software for an industry” in the abstract. It’s an industry operating system: it understands the nouns and verbs of the job, encodes constraints, reduces risk, and speeds decisions inside a workflow people trust.
Historically, the strongest vertical businesses shared a familiar pattern:
- High pricing power (often shocking vs horizontal SaaS)
- Retention in the mid-90s
- Defensibility rooted in habit + workflow lock-in, not just features
You’ve heard it in leadership meetings: “We’re a [vendor] house.”
That certainty is rarely about perfection. It’s about human switching costs: training, shortcuts, internal knowledge, and the quiet fear of breaking what already “works”.
LLMs don’t delete this model, but they change the basis of defensibility. The uncomfortable bit is that this can be structurally true long before it shows up cleanly in the numbers.
Two buckets of moats (and why this matters)
I separate moats into two buckets, because it stops hand-waving:
- Interface + workflow moats (where many incumbents have historically monetised)
- Structural moats (scarce inputs, regulation, networks, transactions, liability)
LLMs don’t hit these equally. And most businesses know, deep down, which bucket they’re really in.
Ten moats, rewritten through an LLM lens
1) Learned interfaces get flattened, fast
A surprising amount of “lock-in” is just learned behaviour: proprietary navigation, shortcuts, weird reporting flows, and internal champions who “know the system”.
LLMs collapse that. When the interface becomes “in plain English, get me X, compare Y, draft Z, show evidence, format for my boss”, years of UI muscle memory loses value quickly.
If your defensibility story is “users are trained on our platform”, your moat is eroding faster than your renewal report will admit.
2) Workflow logic shifts from code to instructions
Vertical vendors have encoded domain expertise into software for decades: validations, rules, compliance checks, edge cases, orchestration logic.
LLMs don’t remove code — but they let domain experts express playbooks in a form systems can execute far faster than the old “spec → build → QA → release” cycle.
Board implication: the question stops being “how much workflow logic have we built?” and becomes:
How much of this must live inside our proprietary product — and how much can be recreated as AI instructions layered over someone else’s tools?
3) Public (or easily licensable) data gets commoditised
Many information products made public/standard data usable: normalising, linking, ranking, and packaging it so professionals could trust it under time pressure.
Frontier models are increasingly universal parsers + synthesis engines. If the underlying data is public (or the same licences are available to everyone), the accessibility layer becomes less defensible — and less priceable.
If your value proposition is “we make standard data searchable”, you’re in the blast radius.
4) Talent scarcity flips from barrier to accelerator
Pre-LLM, winning in vertical often required “bilingual” teams: engineers who understood the domain and domain experts who could translate reality into product.
LLMs reduce the engineering bottleneck for a lot of work. Domain experts suddenly have more leverage: they can prototype high-value behaviours without waiting on backlog.
Competition doesn’t go from three credible players to four. It goes from three to thirty — and then a hundred. The constraint becomes distribution and trust, not headcount.
5) Bundling weakens because the agent becomes the bundle
Classic vertical growth: bundle adjacent modules and expand share of wallet.
Agentic workflows challenge that, because the agent can orchestrate best-of-breed under one interface. Suite vs point solution becomes less relevant, directionally, as the interface abstracts providers away.
If your plan depends on module bundling to defend margins, expect tougher renewals and more pressure to prove outcomes (not breadth).
6) Truly proprietary data gets more valuable – but most businesses overclaim it
Here’s the paradox: scarce inputs become more valuable in an LLM world, not less. Models and agents still need high-quality, exclusive fuel.
But “proprietary” gets abused.
Not proprietary:
- “We organise it better”
- “We built a nicer UI”
- “Users prefer our dashboards”
Proprietary is:
- exclusive relationships / unique feeds
- hard-to-replicate historical corpuses
- regulated opinions with liability
- structurally expensive acquisition processes
Boards should be ruthless here. This is where survivors separate from suppliers.
7) Regulation and compliance lock-in remains structural
In regulated environments, switching cost is driven by certification, auditability, governance, and liability – not interface familiarity.
LLMs don’t remove the need for audit trails and controlled processes. In many cases, AI slows adoption unless the vendor can provide a safe, traceable environment.
If you’re compliance-anchored, you’re less exposed near-term, but governance becomes a product capability, not a slide in a deck.
8) Network effects stay sticky even if the UI changes
Where value comes from who else is on the platform — collaboration graphs, ecosystem participation, shared context — LLMs don’t “break” the network.
The interface may shift. The value of the graph remains.
If you’re the communications layer, your moat isn’t the UI, it’s the network.
9) Transaction embedding is durable because it’s infrastructure
If you sit in money flow; payments, claims, settlement, reconciliation — you’re closer to infrastructure than software.
LLMs can sit on top of the rails and make them easier to operate. But replacing the rails is harder because reliability, compliance, uptime, and liability matter more than delight.
Rails businesses tend to be more resilient than research surfaces.
10) Systems of record hold — but the long-term threat is the agent becoming the layer of truth
Systems of record are sticky because leaving is risky: migrations fail, audit trails break, workflows shatter, and careers get bruised.
LLMs won’t displace systems of record overnight.
But they can become a new “memory layer” across tools — email, docs, chat, CRM, file stores. When an agent sees everything and remembers everything, the interface becomes the relationship… and eventually the relationship becomes the place users trust most.
Board lens: your system of record moat holds today, but what happens if your product becomes “the database behind someone else’s interface”?
Why the market can be right before revenue moves
Markets don’t wait for churn. They reprice the multiple the moment the moat thesis cracks.
Even if revenue is contractually sticky for 12–24 months, you can be repriced from “premium multiple with pricing power” to “interchangeable supplier under someone else’s interface” and that alone can justify a nasty drawdown.
The revenue cliff is usually a slope:
- “We’ll renew, but we want a discount”
- Then “we’re unbundling modules”
- Then “we’re standardising on a new workflow layer”
- Then churn arrives later
The real threat is a pincer movement
It’s not “one model release kills us”. It’s a pincer:
- AI-native vertical entrants build credible products faster and cheaper → fragmented supply → pricing power collapses
- Horizontal platforms go deep because they already own distribution, identity, budgets, and daily usage → AI lets them verticalise without selling a new platform
Cheaper specialists below. Powerful distributors above. The middle ground gets squeezed — and that’s where a lot of historical value capture lived.
When vertical software goes “headless”
A mental model I use with exec teams: vertical software goes “headless” — economically.
The interface moves to the agent. The user’s relationship shifts from your product to their assistant.
In that world, margin and relationship accrue to whoever owns:
- The interface
- The workflow definitions (skills/playbooks)
- The routing across tools + data
If you don’t have proprietary data, regulatory lock-in, network effects, or transaction embedding, you risk becoming an interchangeable supplier: technically important, commercially pressured, constantly renegotiated.
A blunt board-level risk test
If I want this to be practical, I come back to three unromantic questions:
- Is the data truly proprietary — meaning others cannot realistically obtain or recreate it?
- Do you have regulatory/compliance lock-in that keeps switching costs structurally high even if the UI changes?
- Are you embedded in transactions where reliability and liability dominate?
- No to all three: high risk, multiple compression is rational
- Yes to one: medium risk, segment mix matters
- Yes to two or three: lower risk (not immune, but far less likely to be commoditised)
What I’d be pushing as a NED right now
If I’m on the board of a vertical software or data business today, I’m not asking for a typical “AI feature roadmap”. That’s how you lose: ship a chatbot, tick a box, and miss the economic shift.
I’d drive five workstreams immediately:
- A brutal moat audit: what’s interface/workflow vs what’s structural
- A real data strategy: exclusivity, provenance, defensibility — scarce inputs win
- Governance as product: audit trails, permissioning, traceability, controlled AI
- Distribution + daily user love: if users don’t rely on you day-to-day, you’ll be renegotiated first
- A clear agent strategy:
- Are we building the agent layer?
- Are we a premium data supplier into other agents?
- Or are we partnering — and packaging/pricing for the new power structure?
Because the real risk isn’t that AI “arrives”.
It’s that the interface changes, and you wake up one day owning far less of the relationship than you thought.
The reckoning isn’t “everything dies”
It’s the market finally distinguishing between:
- Businesses defensible because they owned something scarce, and
- Businesses defensible because they owned a learned interface wrapped around licensable data and embedded habit
The winners won’t treat AI as a feature add.
They’ll treat it as a structural redesign: get honest about where value capture is moving, double down on moats LLMs can’t dissolve, and decide – deliberately – whether they’re going to own the agent layer, feed it, or get priced by it.

